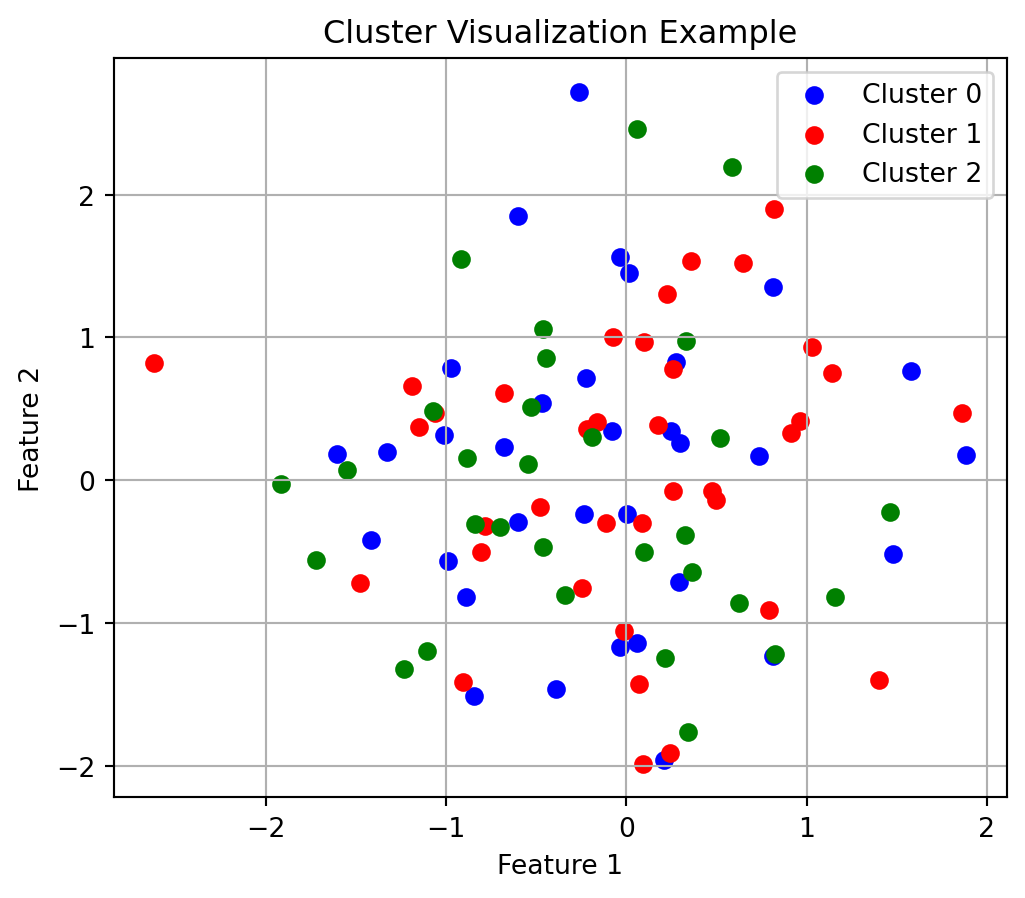
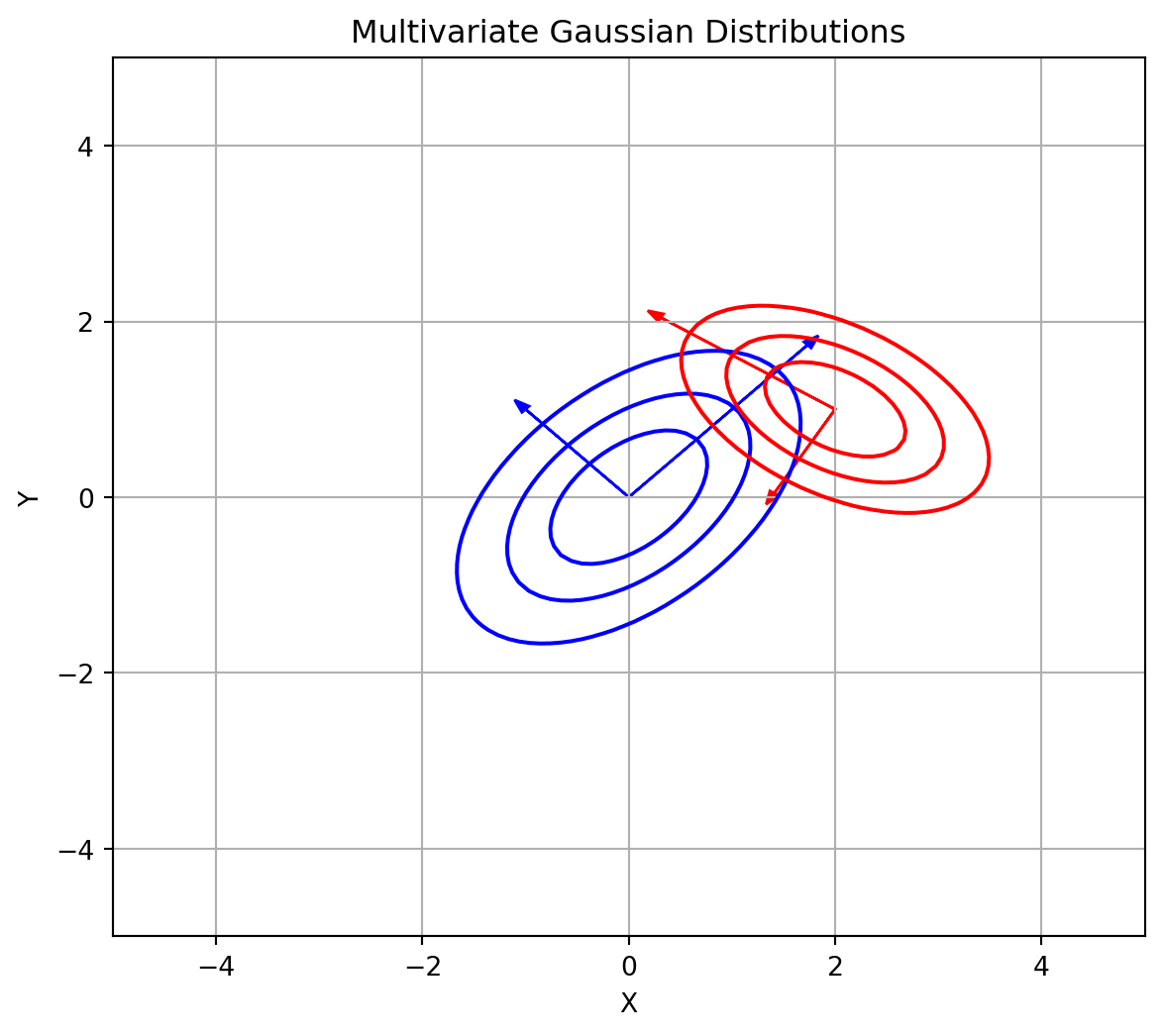
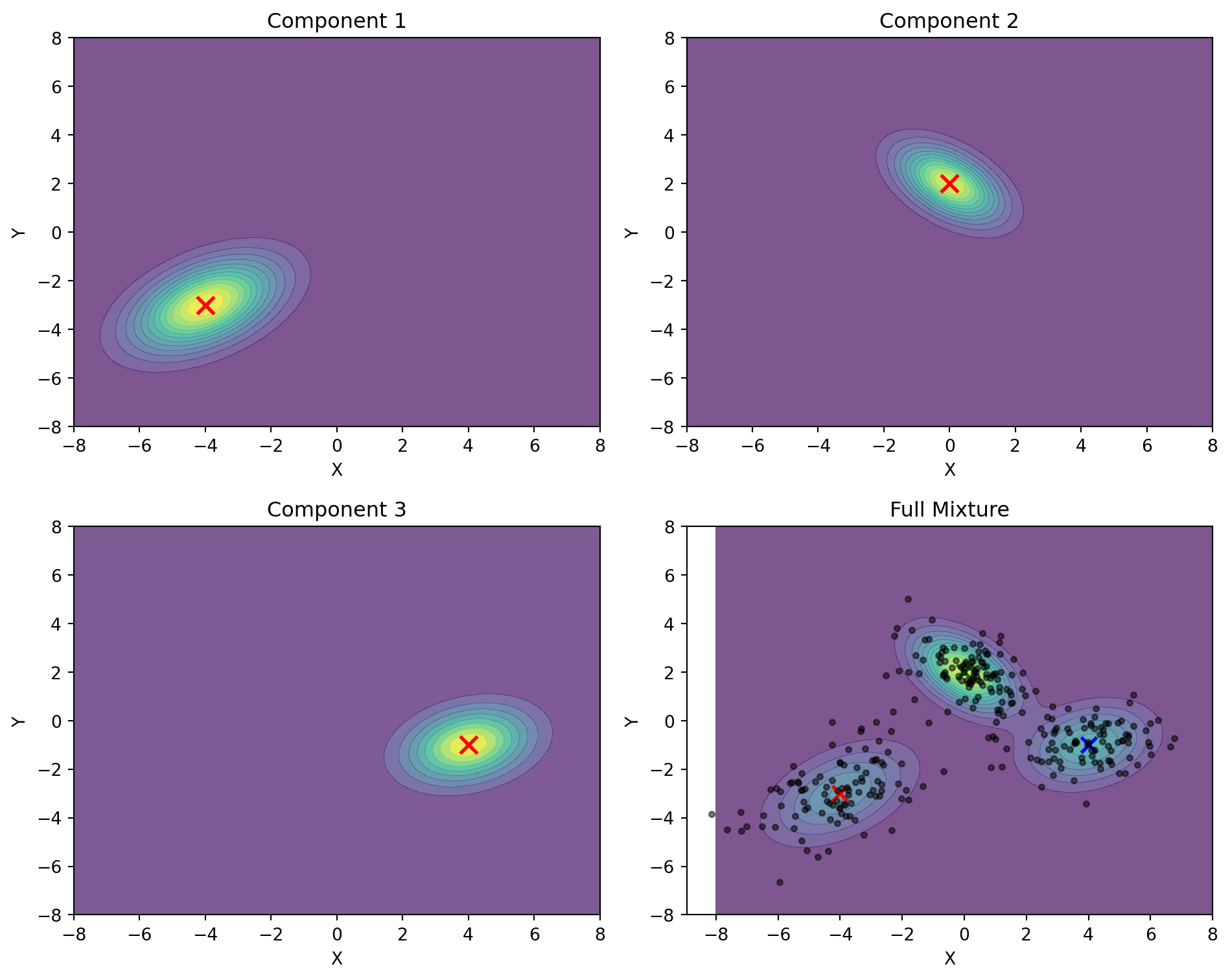
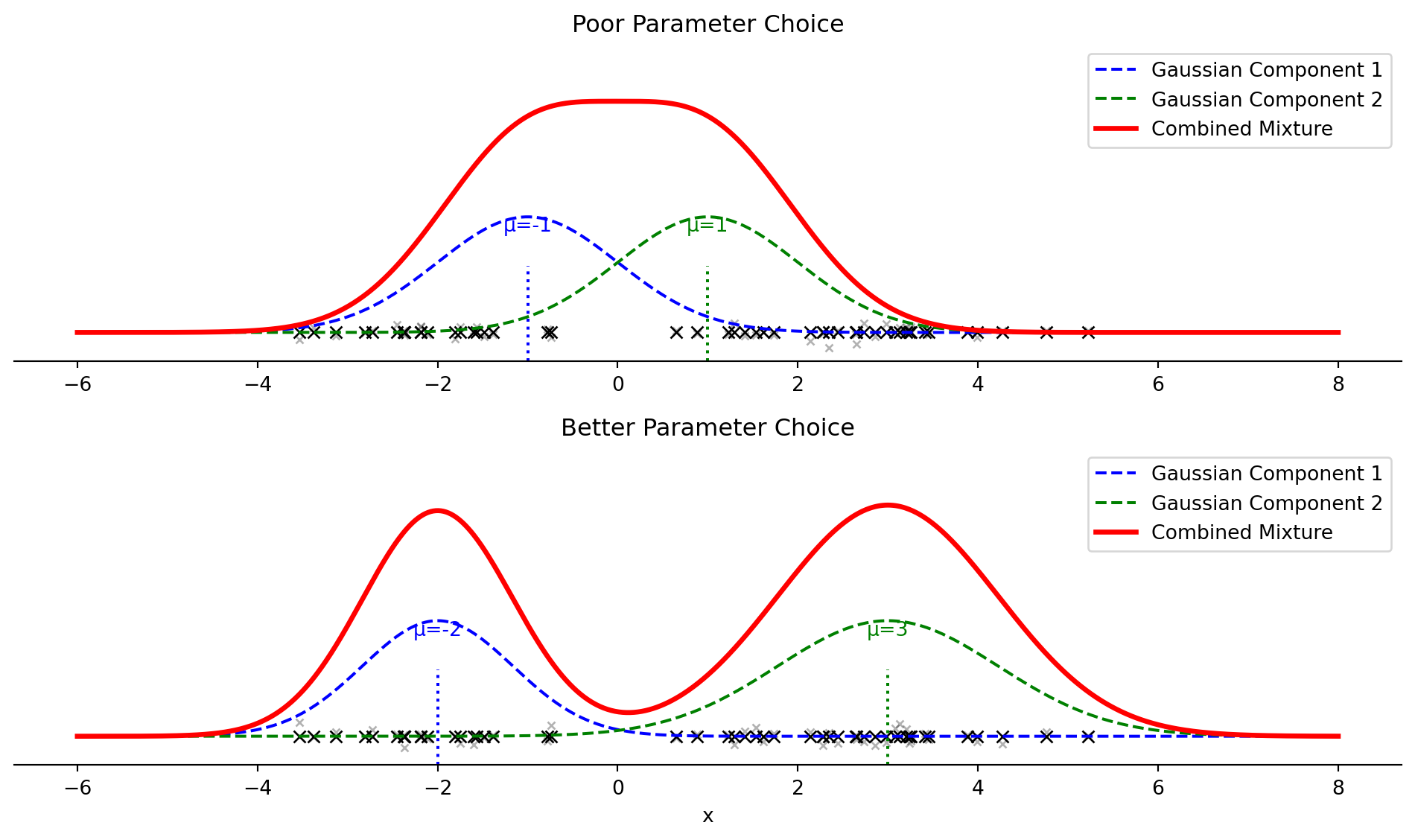
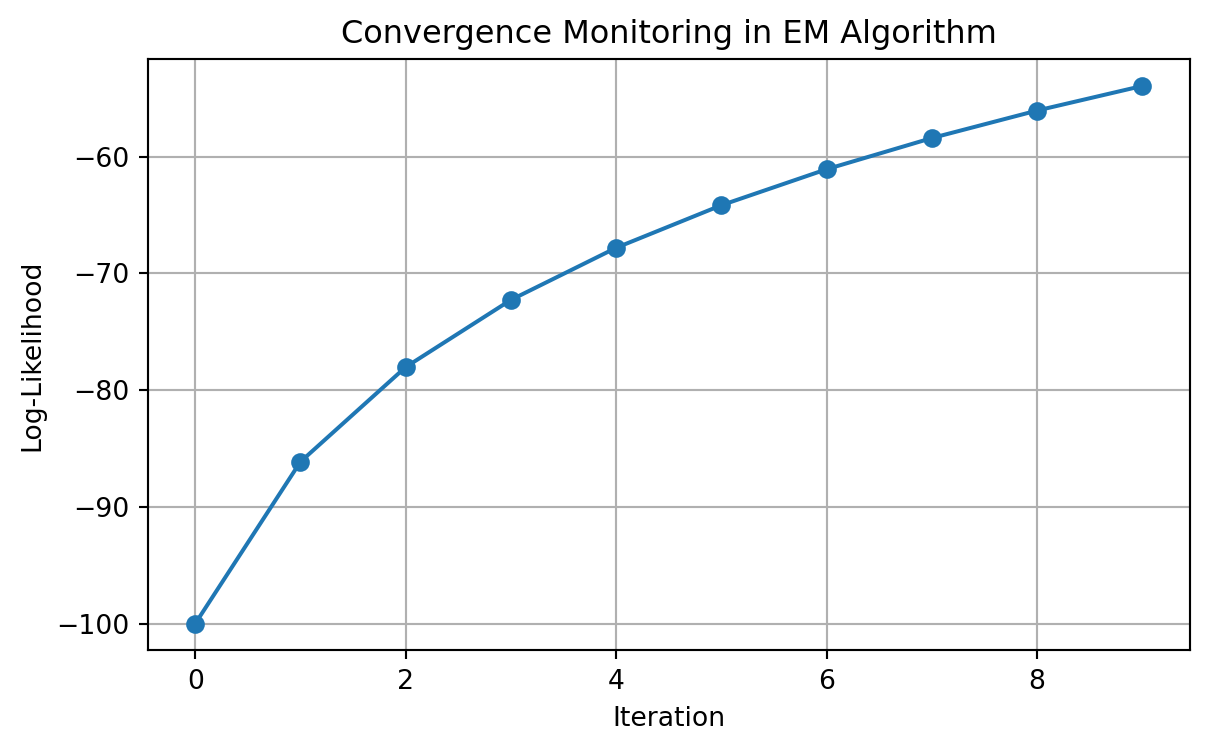
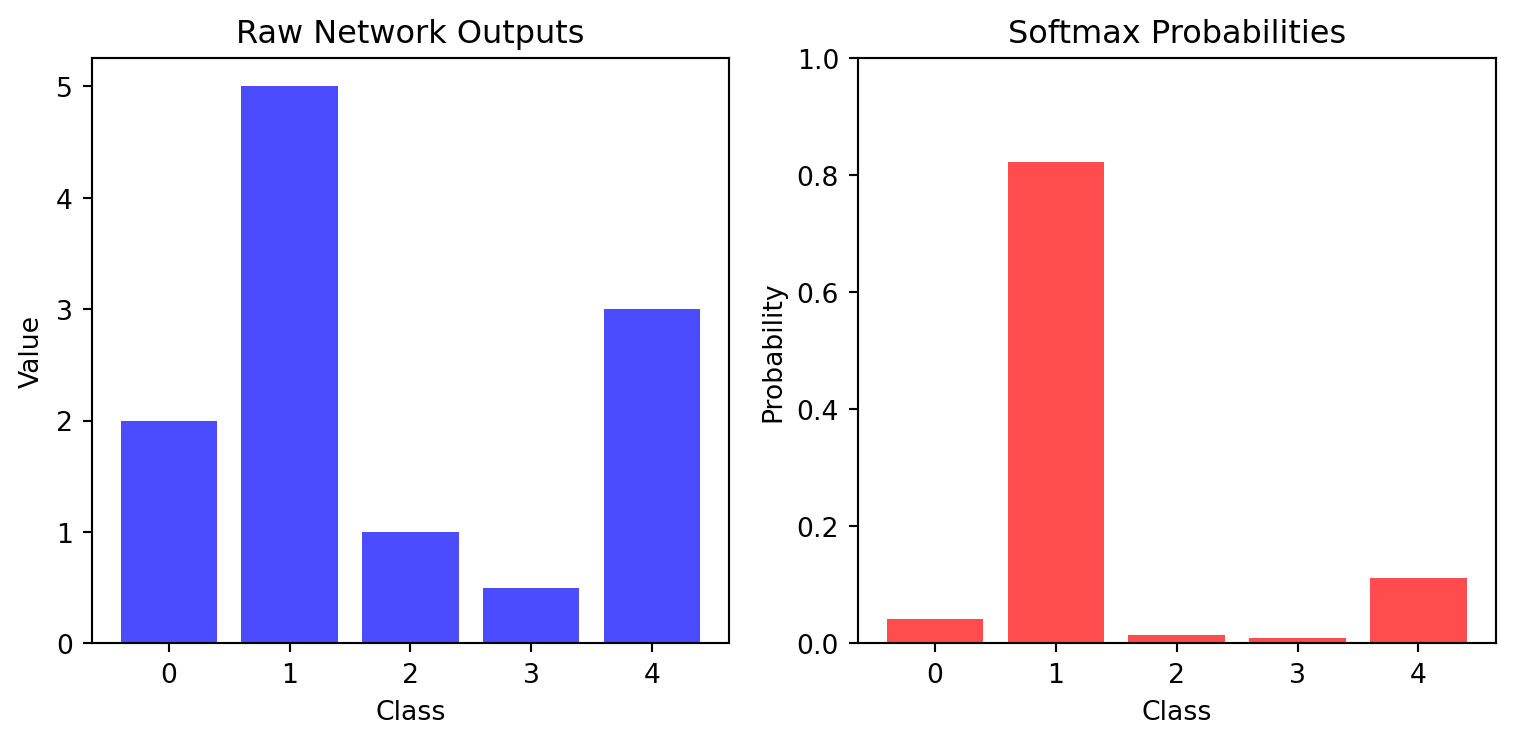
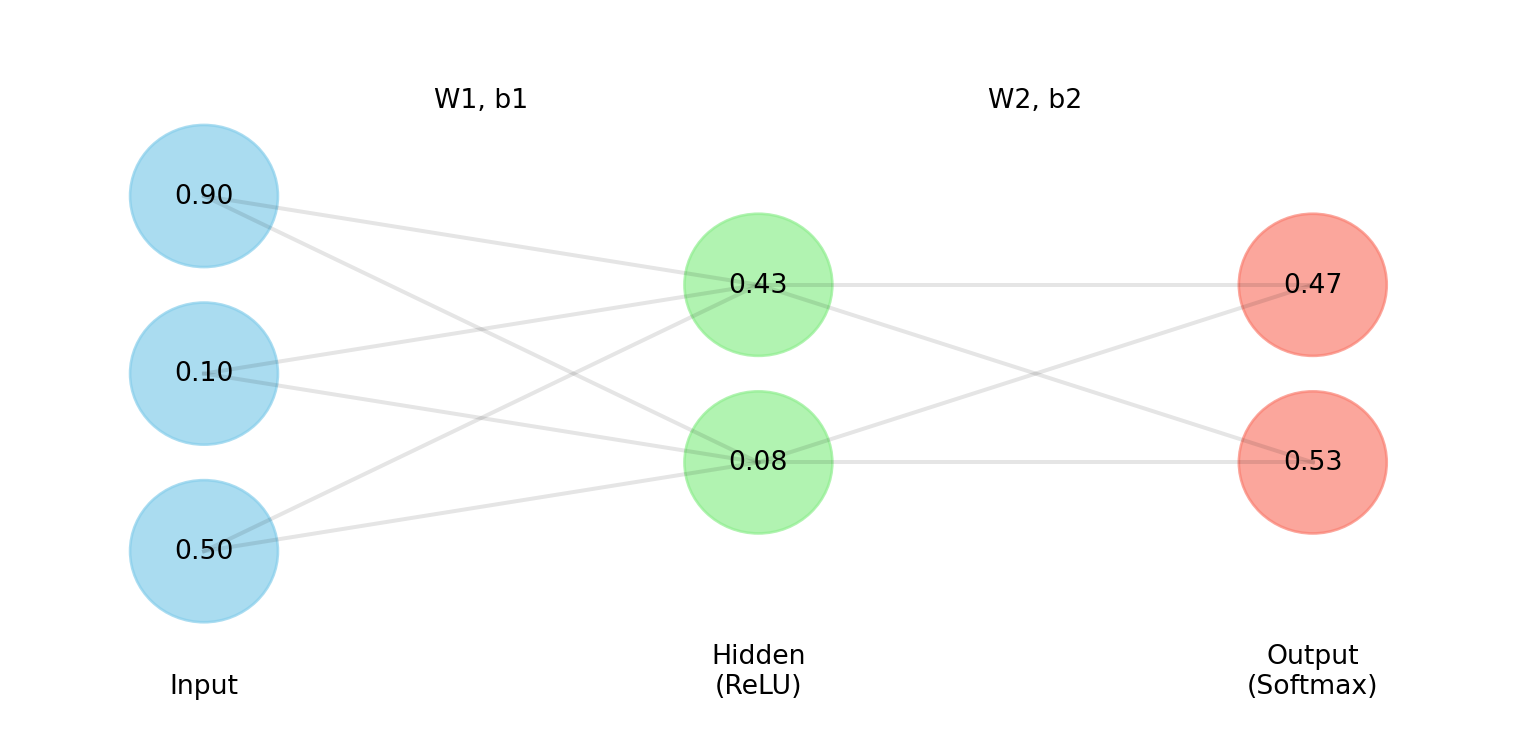
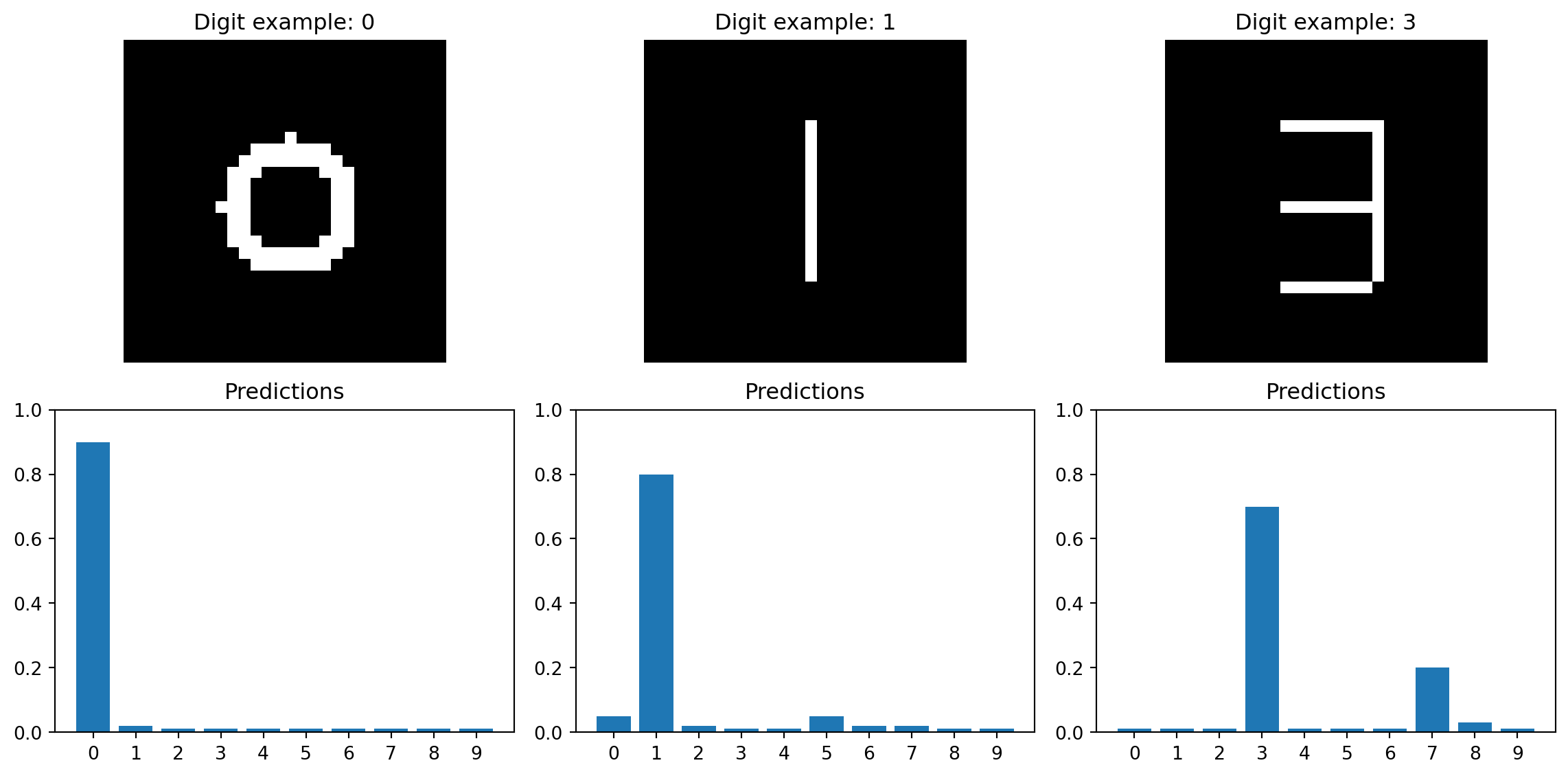
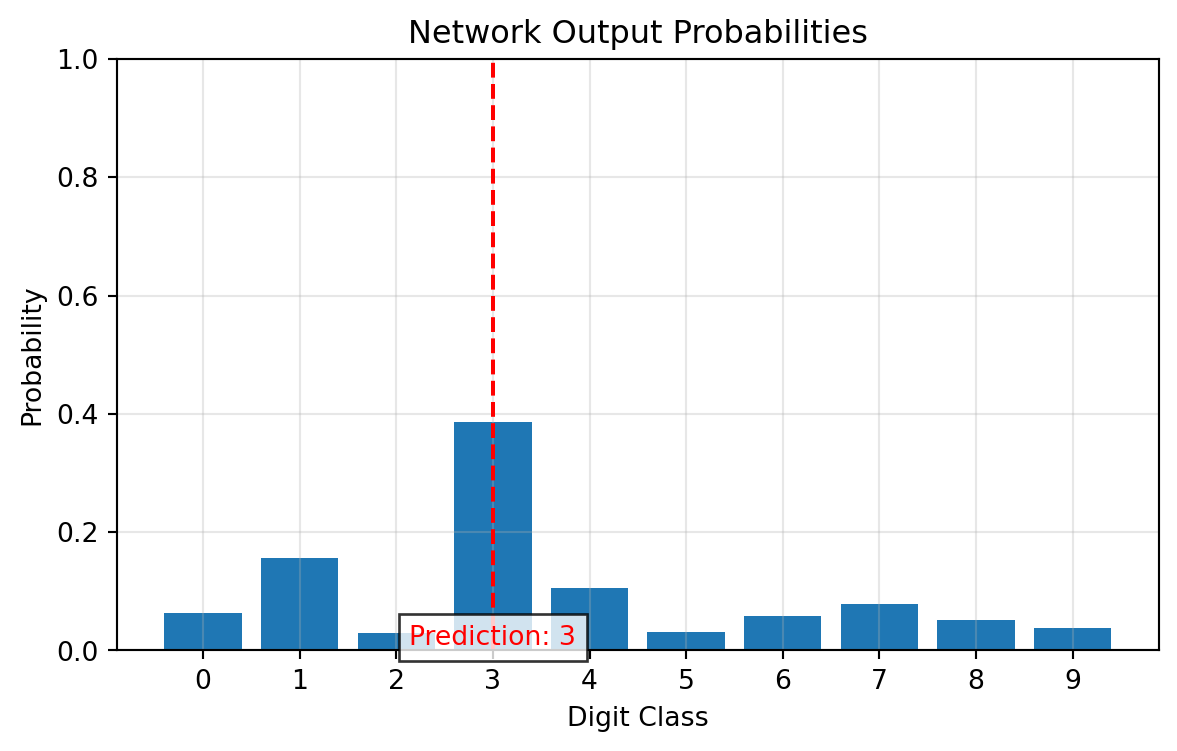
# Demonstrate a 3-component GMM in 2D
def plot_gmm_components():
# Create grid
x = np.linspace(-8, 8, 100)
y = np.linspace(-8, 8, 100)
X, Y = np.meshgrid(x, y)
pos = np.empty(X.shape + (2,))
pos[:, :, 0] = X
pos[:, :, 1] = Y
# Define 3 Gaussian components
means = [
np.array([-4, -3]),
np.array([0, 2]),
np.array([4, -1])
]
covs = [
np.array([[2, 0.8], [0.8, 1.5]]),
np.array([[1, -0.5], [-0.5, 1]]),
np.array([[1.5, 0.3], [0.3, 1]])
]
weights = [0.3, 0.4, 0.3] # Mixing weights
# Create individual Gaussians
rv1 = multivariate_normal(means[0], covs[0])
rv2 = multivariate_normal(means[1], covs[1])
rv3 = multivariate_normal(means[2], covs[2])
# Create figure with subplots
fig, axs = plt.subplots(2, 2, figsize=(10, 8))
# Plot individual components
component_pdfs = []
titles = ["Component 1", "Component 2", "Component 3", "Full Mixture"]
components = [
rv1.pdf(pos),
rv2.pdf(pos),
rv3.pdf(pos),
weights[0] * rv1.pdf(pos) + weights[1] * rv2.pdf(pos) + weights[2] * rv3.pdf(pos)
]
# Random sample data from the mixture
np.random.seed(42)
n_samples = 300
mixture_samples = []
# Draw samples from the mixture
for _ in range(n_samples):
# Choose component based on weights
component = np.random.choice(3, p=weights)
# Draw from selected component
if component == 0:
sample = np.random.multivariate_normal(means[0], covs[0])
elif component == 1:
sample = np.random.multivariate_normal(means[1], covs[1])
else:
sample = np.random.multivariate_normal(means[2], covs[2])
mixture_samples.append(sample)
mixture_samples = np.array(mixture_samples)
# Plot each component and the mixture
for i, (ax, pdf, title) in enumerate(zip(axs.flat, components, titles)):
contour = ax.contourf(X, Y, pdf, cmap='viridis', alpha=0.7, levels=12)
ax.set_title(title)
ax.set_xlabel('X')
ax.set_ylabel('Y')
# Add component means
if i < 3:
ax.scatter(means[i][0], means[i][1],
color='red', s=100, marker='x', linewidth=2)
else:
# In the full mixture plot, show all means and the data points
for j, mean in enumerate(means):
ax.scatter(mean[0], mean[1],
color=['r', 'g', 'b'][j], s=80, marker='x', linewidth=2)
# Add the mixture data points
ax.scatter(mixture_samples[:, 0], mixture_samples[:, 1],
color='black', s=10, alpha=0.5)
plt.tight_layout()
plt.show()
plot_gmm_components()