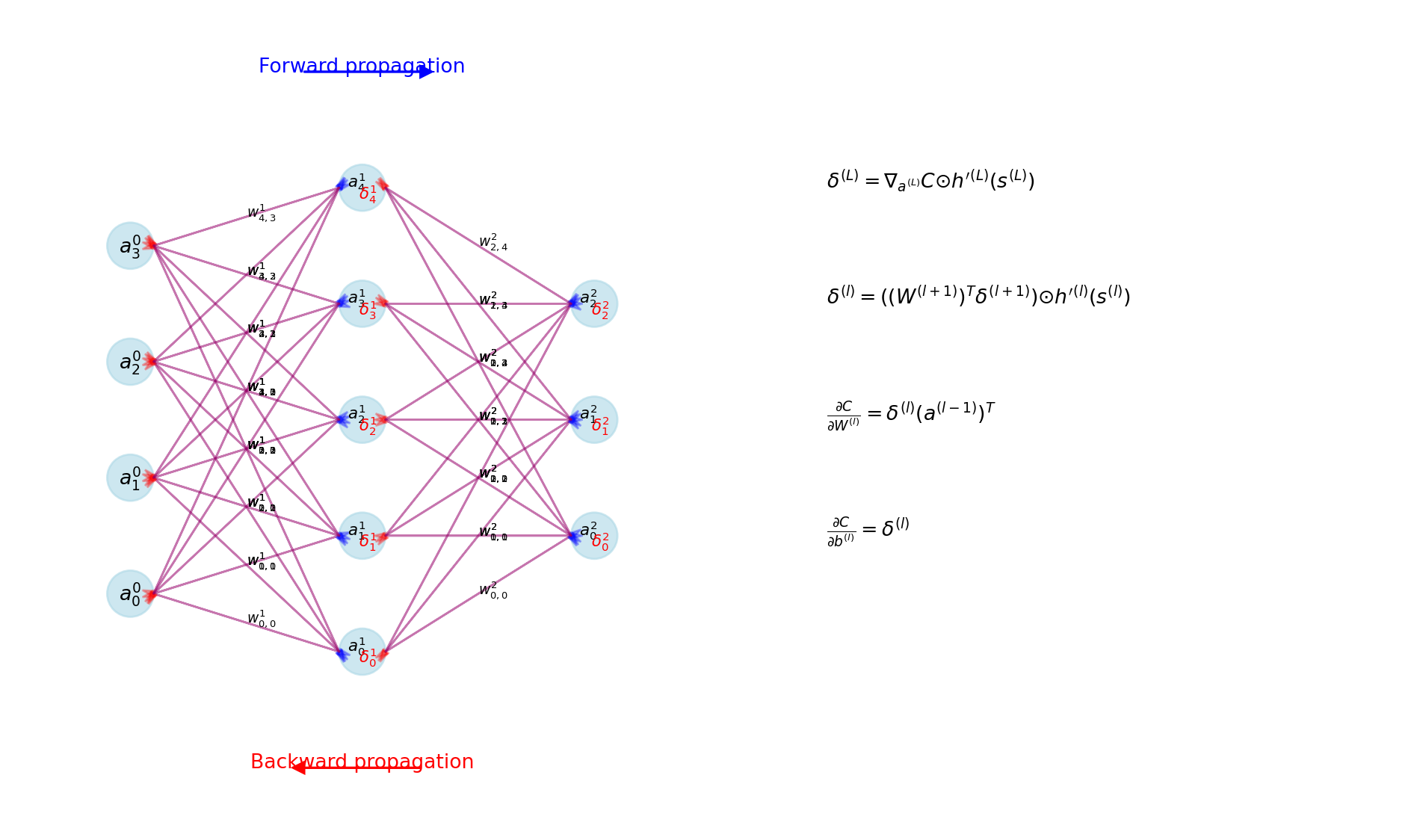
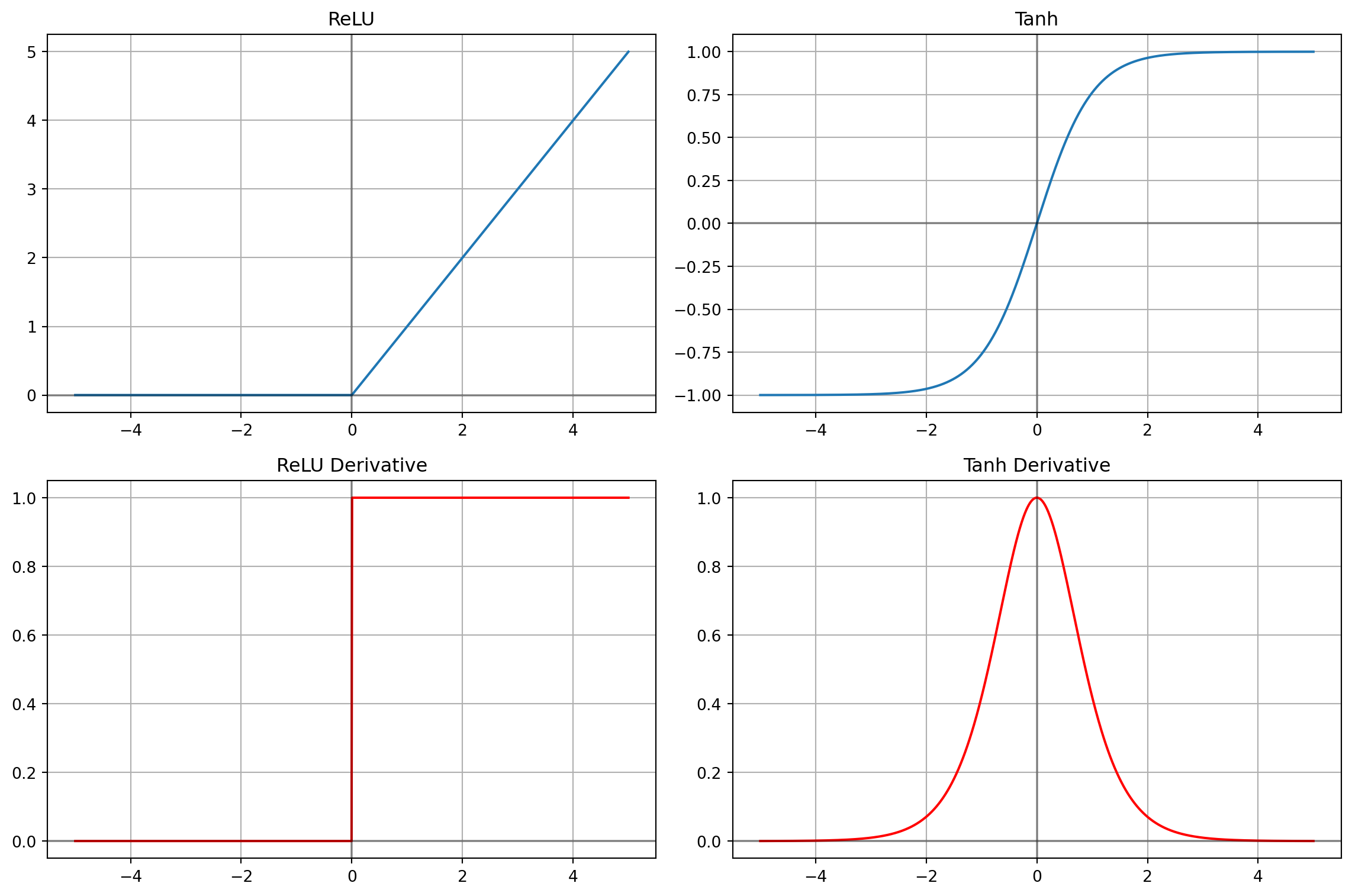
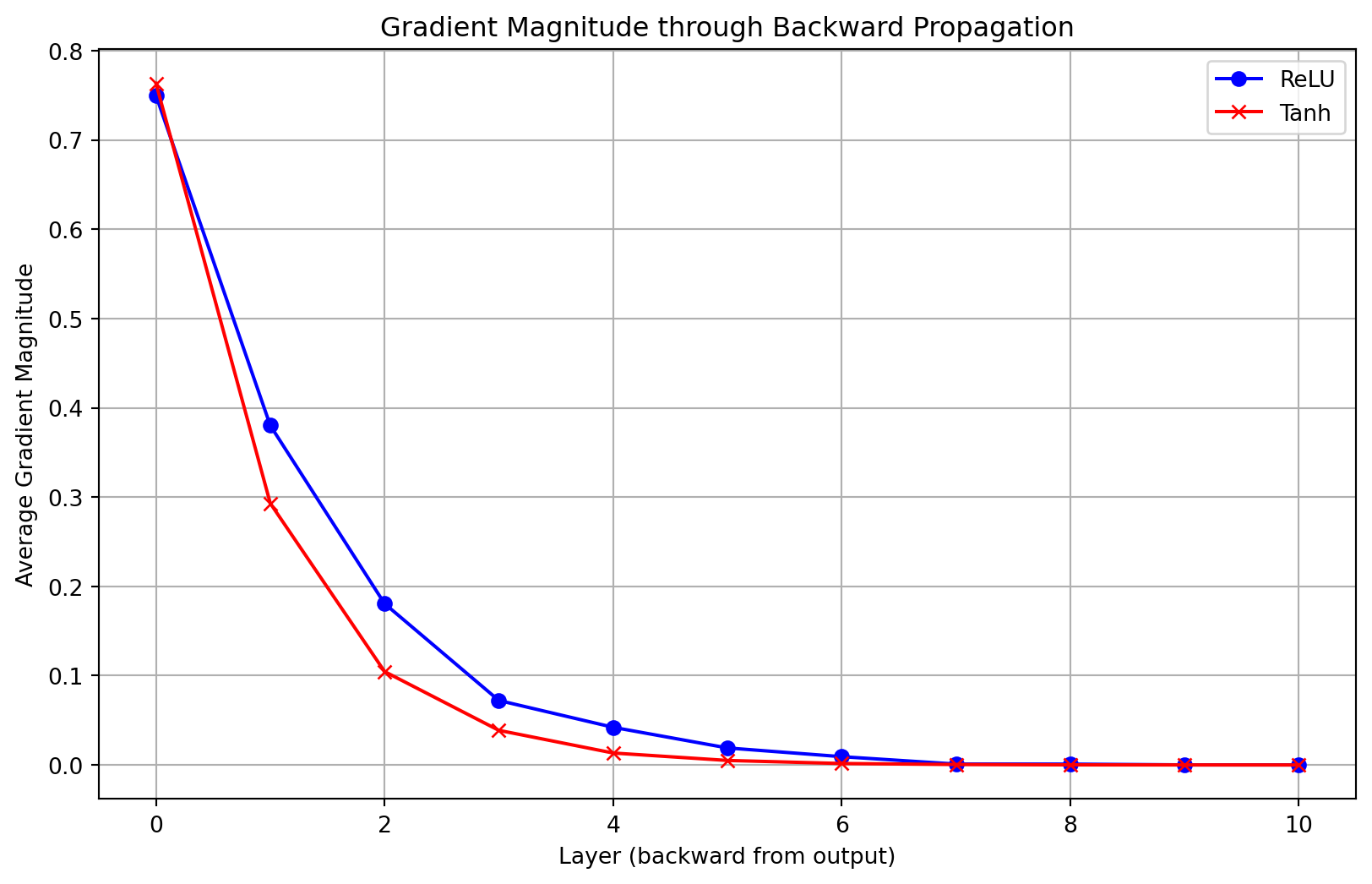
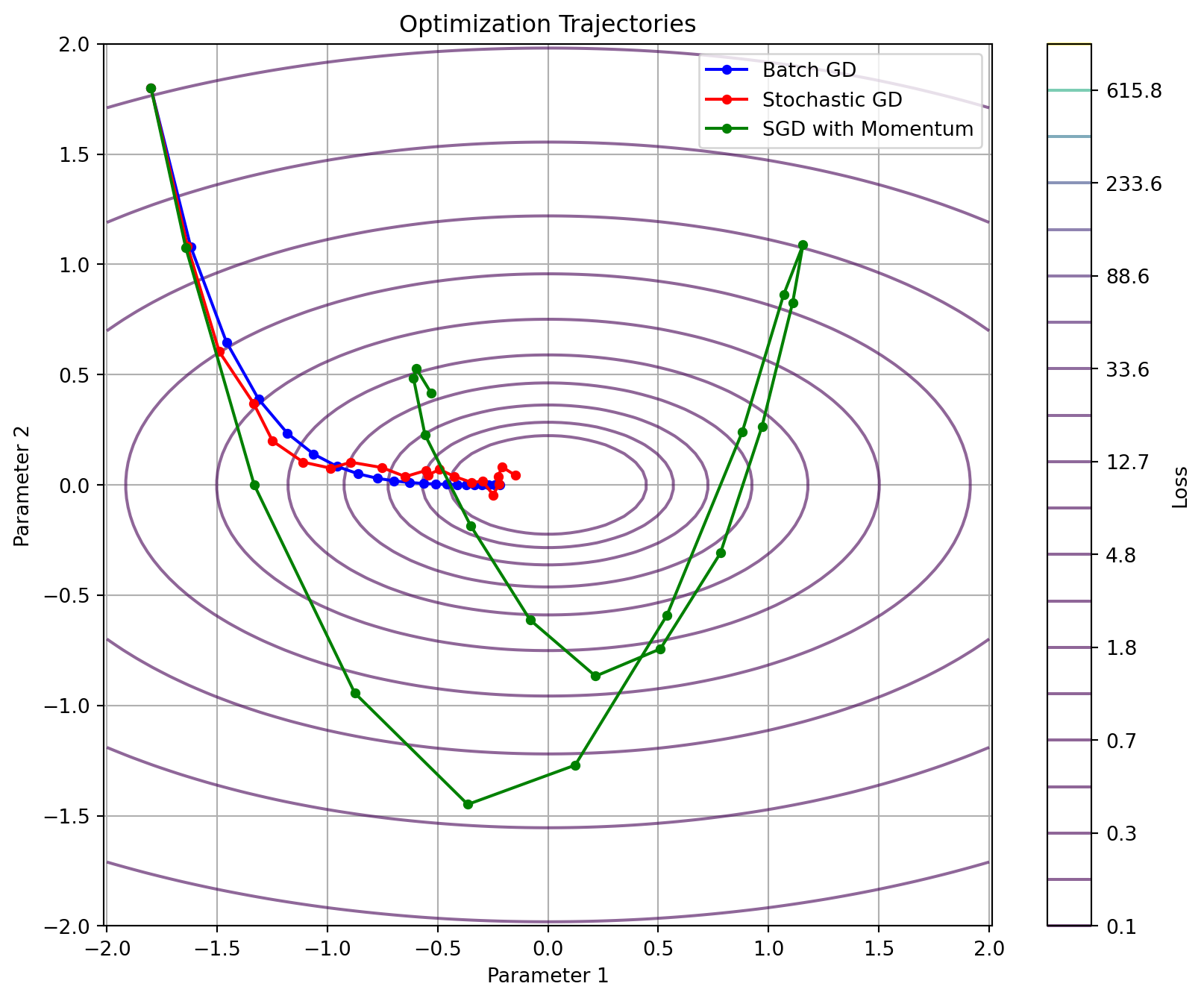
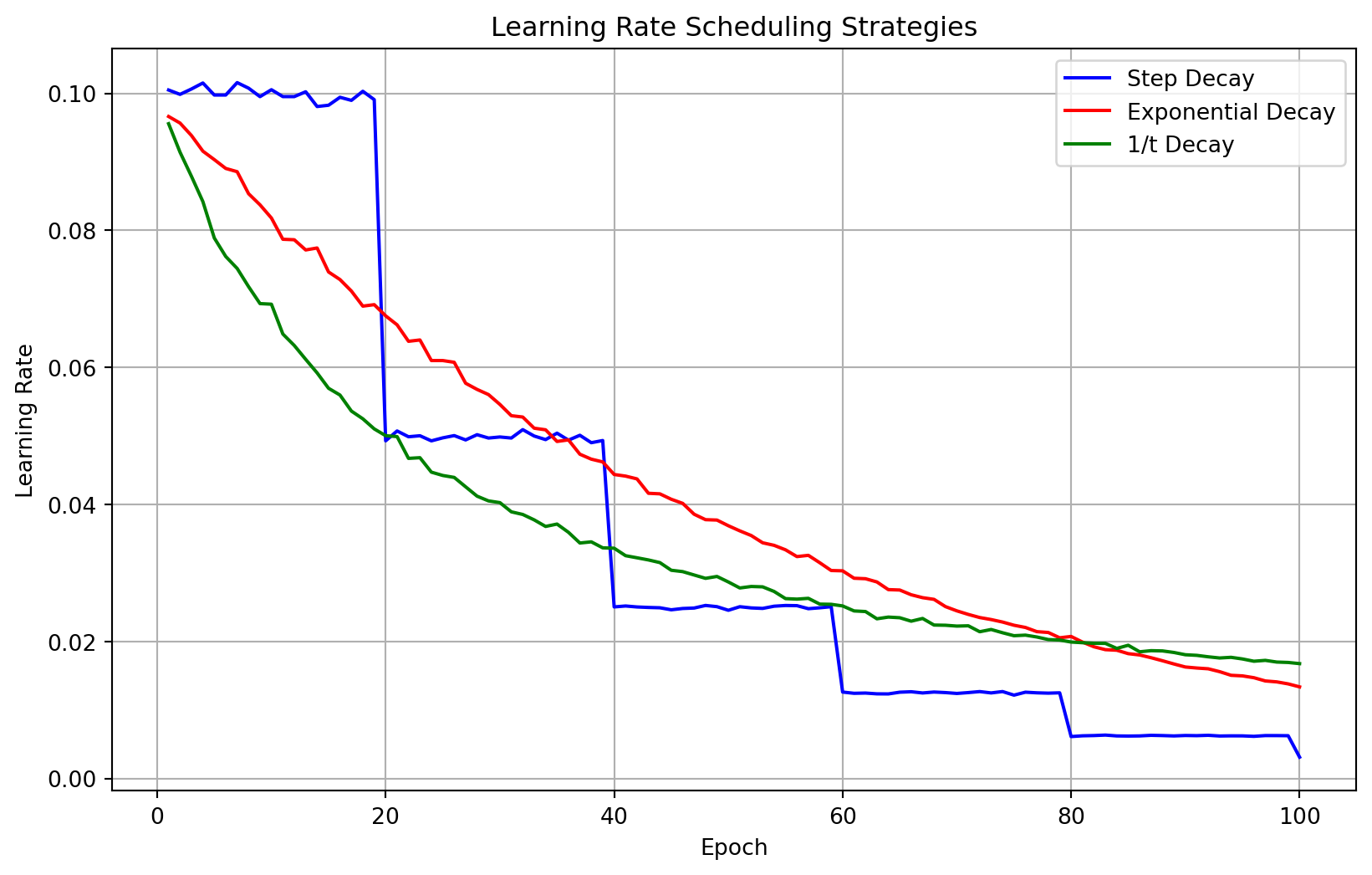
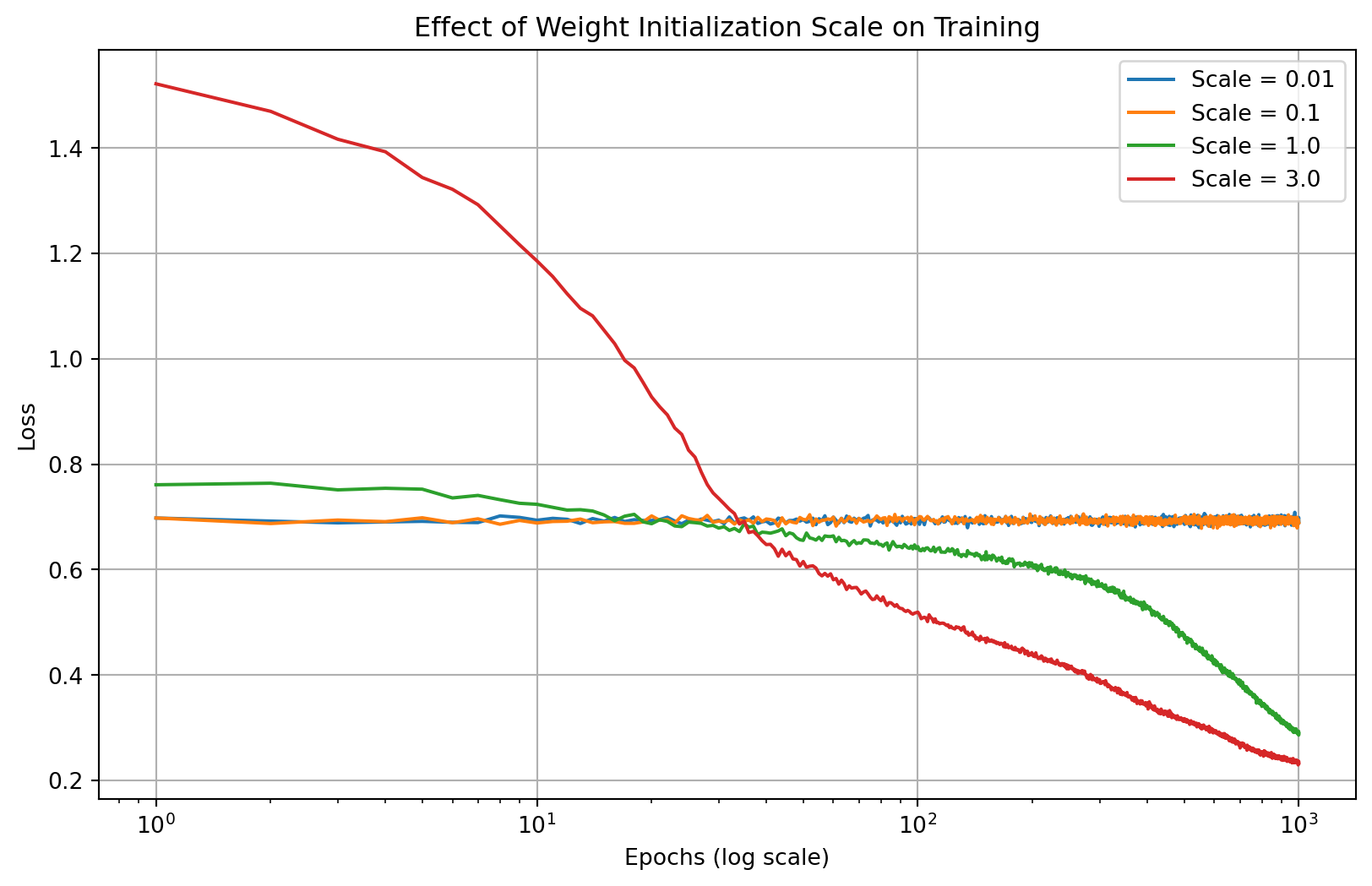
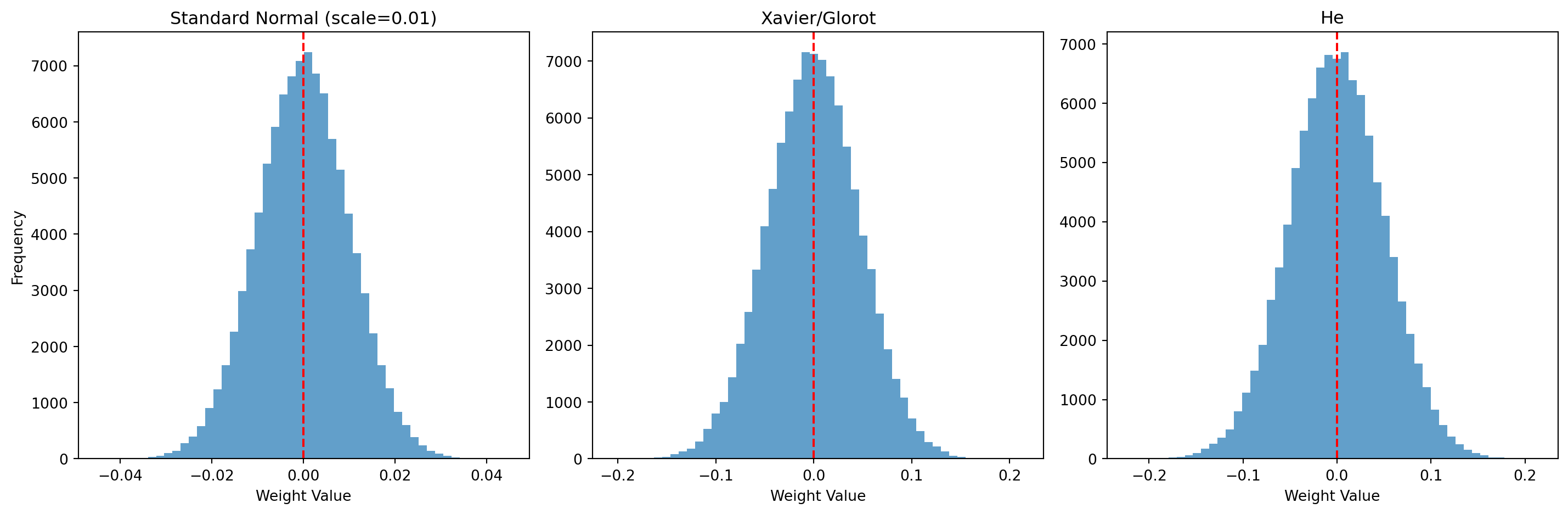
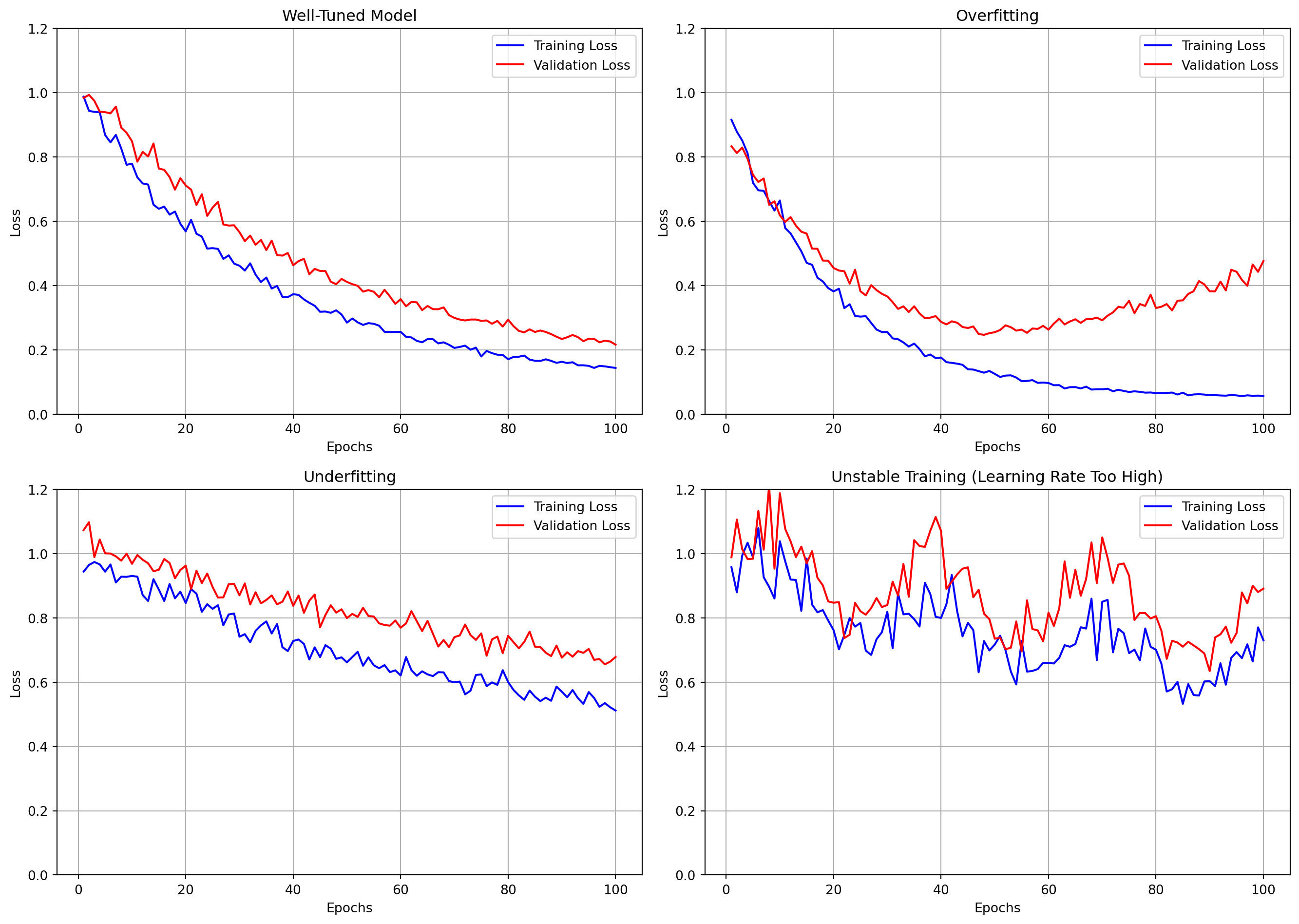
#| label: fig-regularization
#| fig-cap: "Effect of regularization on model fit and weight distributions"
# TODO: fix, exploding gradient issue
import numpy as np
import matplotlib.pyplot as plt
def demonstrate_regularization_effects():
"""Visualize how regularization affects model fit and weight distribution"""
np.random.seed(42)
# Generate synthetic data
n_samples = 150
X = np.linspace(-3, 3, n_samples).reshape(-1, 1)
true_function = lambda x: np.sin(x) + 0.3 * x
y = true_function(X) + np.random.normal(0, 0.2, size=X.shape)
# Split into train and test
train_idx = np.random.choice(n_samples, int(0.8 * n_samples), replace=False)
test_idx = np.array(list(set(range(n_samples)) - set(train_idx)))
X_train, y_train = X[train_idx], y[train_idx]
X_test, y_test = X[test_idx], y[test_idx]
# Function to create polynomial features
def create_poly_features(X, degree):
return np.column_stack([X**i for i in range(1, degree+1)])
# Polynomial degree
degree = 15
# Create polynomial features
X_train_poly = create_poly_features(X_train, degree)
X_test_poly = create_poly_features(X_test, degree)
# Train three models: no regularization, L2, and L1
# Function to train a model with different regularization
def train_model(X, y, l2_lambda=0, l1_lambda=0, iterations=5000):
# Initialize weights randomly
w = np.random.randn(X.shape[1], y.shape[1]) * 0.01
# Add some noise to training process to simulate real conditions
lr = 0.01
losses = []
weight_history = []
for i in range(iterations):
# Predictions
y_pred = X @ w
# Base loss (MSE)
mse_loss = np.mean((y_pred - y)**2)
# Add regularization terms to loss
l2_term = 0
l1_term = 0
if l2_lambda > 0:
l2_term = l2_lambda * np.sum(w**2)
if l1_lambda > 0:
l1_term = l1_lambda * np.sum(np.abs(w))
total_loss = mse_loss + l2_term + l1_term
losses.append(total_loss)
# Store weights periodically
if i % 500 == 0:
weight_history.append(w.copy())
# Compute gradients
# MSE gradient
mse_grad = 2 * X.T @ (y_pred - y) / len(y)
# L2 gradient
l2_grad = 0
if l2_lambda > 0:
l2_grad = 2 * l2_lambda * w
# L1 gradient
l1_grad = 0
if l1_lambda > 0:
l1_grad = l1_lambda * np.sign(w)
# Combined gradient
gradient = mse_grad + l2_grad + l1_grad
# Update weights
w = w - lr * gradient
# Add some noise to weights to simulate stochastic training
if i % 100:
w = w + np.random.normal(0, 0.001, size=w.shape)
return w, losses, weight_history
# Train models with different regularization
w_no_reg, losses_no_reg, wh_no_reg = train_model(X_train_poly, y_train)
w_l2, losses_l2, wh_l2 = train_model(X_train_poly, y_train, l2_lambda=0.1)
w_l1, losses_l1, wh_l1 = train_model(X_train_poly, y_train, l1_lambda=0.1)
# Make predictions
y_pred_no_reg = X_test_poly @ w_no_reg
y_pred_l2 = X_test_poly @ w_l2
y_pred_l1 = X_test_poly @ w_l1
# Calculate test errors
mse_no_reg = np.mean((y_test - y_pred_no_reg)**2)
mse_l2 = np.mean((y_test - y_pred_l2)**2)
mse_l1 = np.mean((y_test - y_pred_l1)**2)
# Plot results
plt.figure(figsize=(15, 10))
# Plot model fits
plt.subplot(2, 2, 1)
plt.scatter(X_train, y_train, color='blue', alpha=0.6, label='Training Data')
plt.scatter(X_test, y_test, color='green', alpha=0.6, label='Test Data')
X_plot = np.linspace(-3, 3, 100).reshape(-1, 1)
X_plot_poly = create_poly_features(X_plot, degree)
plt.plot(X_plot, X_plot_poly @ w_no_reg, 'r-', label=f'No Reg (Test MSE: {mse_no_reg:.4f})')
plt.plot(X_plot, X_plot_poly @ w_l2, 'g-', label=f'L2 Reg (Test MSE: {mse_l2:.4f})')
plt.plot(X_plot, X_plot_poly @ w_l1, 'b-', label=f'L1 Reg (Test MSE: {mse_l1:.4f})')
plt.plot(X_plot, true_function(X_plot), 'k--', label='True Function')
plt.title('Model Fit with Different Regularization')
plt.xlabel('X')
plt.ylabel('y')
plt.legend()
plt.grid(True)
# Plot training curves
plt.subplot(2, 2, 2)
plt.plot(losses_no_reg, 'r-', label='No Regularization')
plt.plot(losses_l2, 'g-', label='L2 Regularization')
plt.plot(losses_l1, 'b-', label='L1 Regularization')
plt.title('Training Loss')
plt.xlabel('Iteration')
plt.ylabel('Loss')
plt.legend()
plt.grid(True)
# Plot final weight distributions
plt.subplot(2, 2, 3)
plt.stem(range(1, degree+1), w_no_reg, 'r', label='No Regularization', markerfmt='ro')
plt.stem(range(1, degree+1), w_l2, 'g', label='L2 Regularization', markerfmt='go')
plt.stem(range(1, degree+1), w_l1, 'b', label='L1 Regularization', markerfmt='bo')
plt.title('Final Weight Values')
plt.xlabel('Polynomial Degree')
plt.ylabel('Weight Value')
plt.legend()
plt.grid(True)
# Plot weight magnitude evolution (L2 norm)
plt.subplot(2, 2, 4)
w_norms_no_reg = [np.linalg.norm(w) for w in wh_no_reg]
w_norms_l2 = [np.linalg.norm(w) for w in wh_l2]
w_norms_l1 = [np.linalg.norm(w) for w in wh_l1]
iterations = np.arange(0, 5000, 500)
plt.plot(iterations, w_norms_no_reg, 'r-o', label='No Regularization')
plt.plot(iterations, w_norms_l2, 'g-o', label='L2 Regularization')
plt.plot(iterations, w_norms_l1, 'b-o', label='L1 Regularization')
plt.title('Weight Magnitude Evolution')
plt.xlabel('Iteration')
plt.ylabel('Weight L2 Norm')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
demonstrate_regularization_effects()