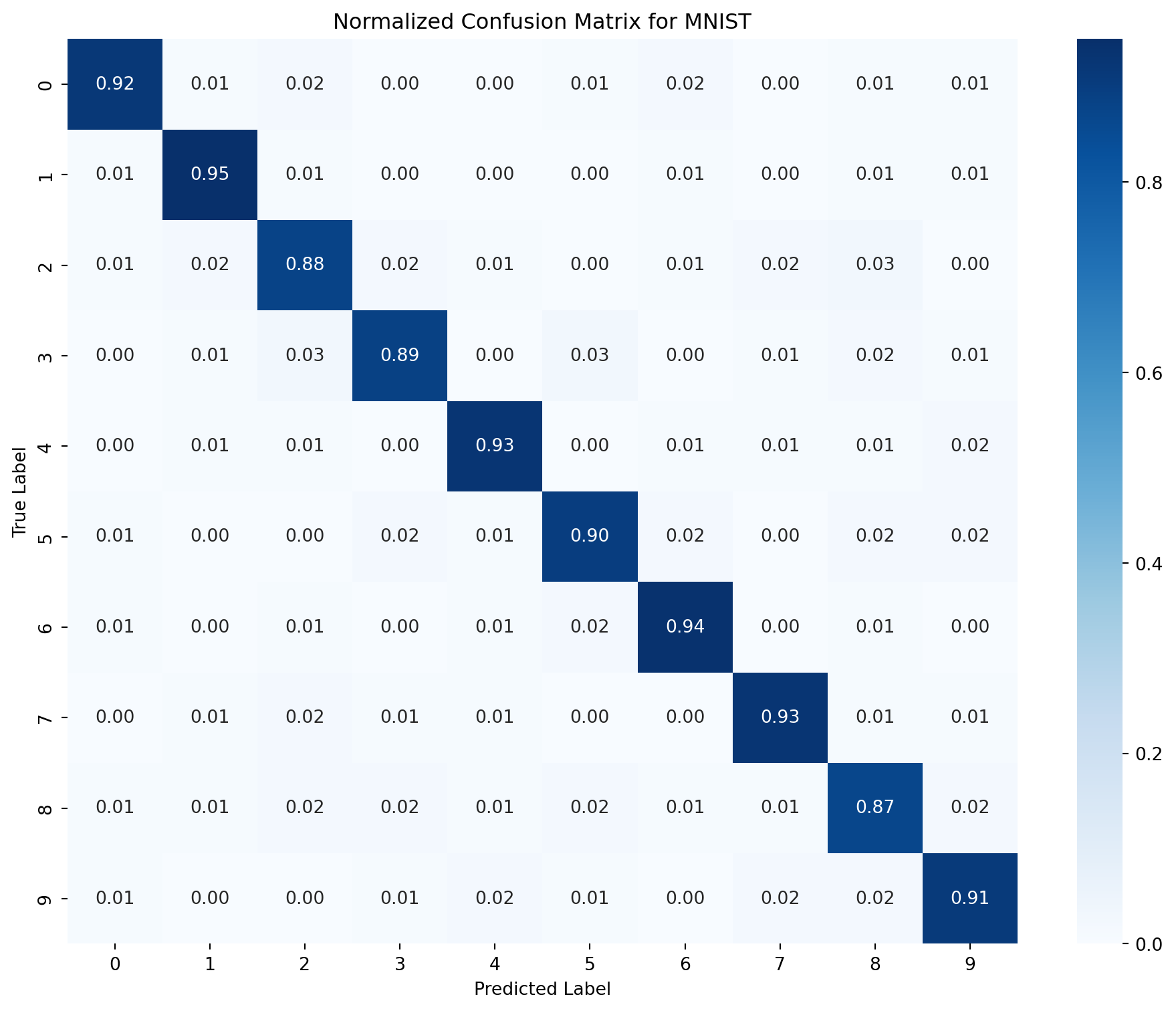
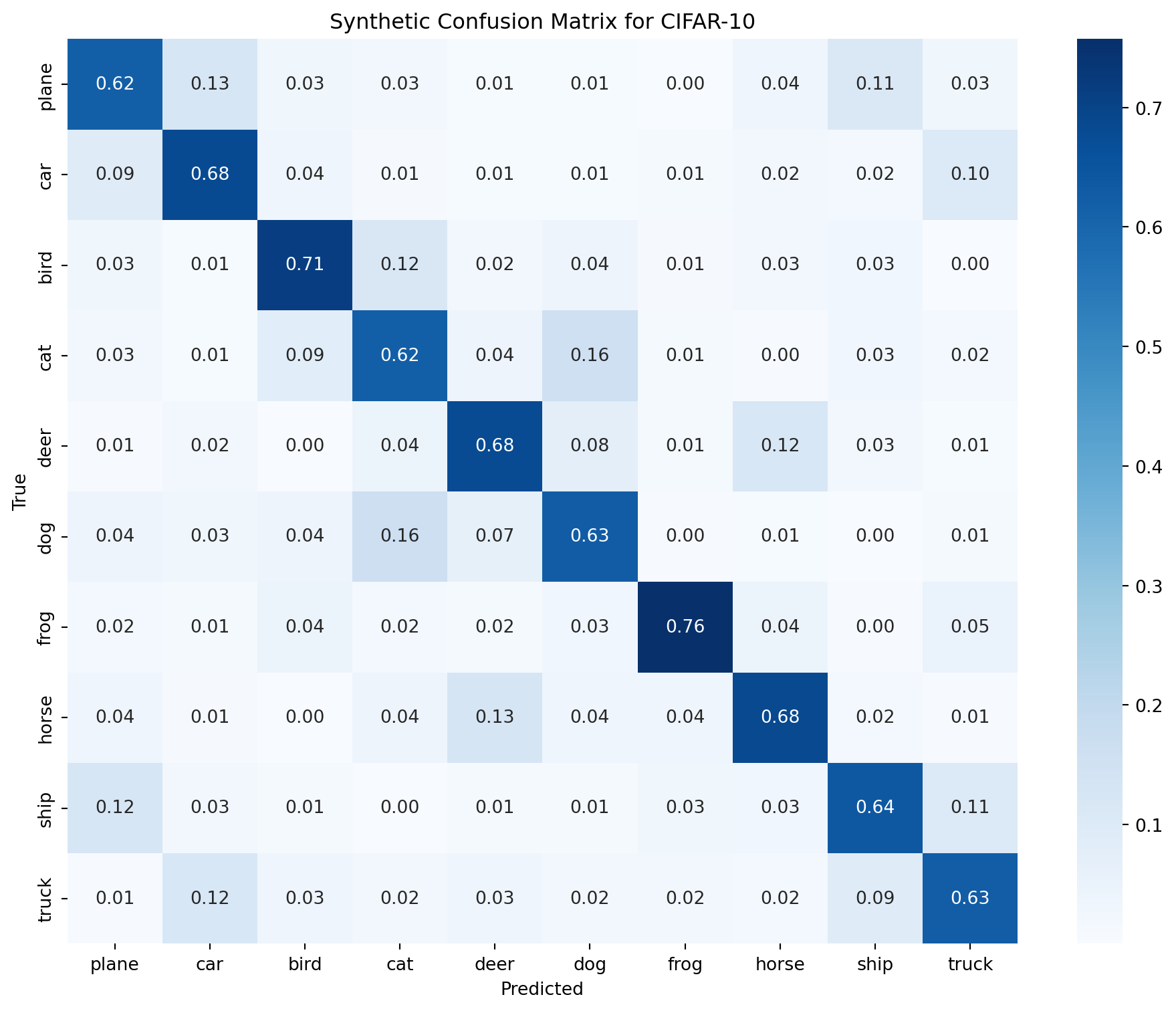
import seaborn as sns
# Simulated confusion matrix for MNIST (normalized)
cm = np.array([
[0.92, 0.01, 0.02, 0.00, 0.00, 0.01, 0.02, 0.00, 0.01, 0.01],
[0.01, 0.95, 0.01, 0.00, 0.00, 0.00, 0.01, 0.00, 0.01, 0.01],
[0.01, 0.02, 0.88, 0.02, 0.01, 0.00, 0.01, 0.02, 0.03, 0.00],
[0.00, 0.01, 0.03, 0.89, 0.00, 0.03, 0.00, 0.01, 0.02, 0.01],
[0.00, 0.01, 0.01, 0.00, 0.93, 0.00, 0.01, 0.01, 0.01, 0.02],
[0.01, 0.00, 0.00, 0.02, 0.01, 0.90, 0.02, 0.00, 0.02, 0.02],
[0.01, 0.00, 0.01, 0.00, 0.01, 0.02, 0.94, 0.00, 0.01, 0.00],
[0.00, 0.01, 0.02, 0.01, 0.01, 0.00, 0.00, 0.93, 0.01, 0.01],
[0.01, 0.01, 0.02, 0.02, 0.01, 0.02, 0.01, 0.01, 0.87, 0.02],
[0.01, 0.00, 0.00, 0.01, 0.02, 0.01, 0.00, 0.02, 0.02, 0.91]
])
plt.figure(figsize=(10, 8))
sns.heatmap(cm, annot=True, fmt='.2f', cmap='Blues', cbar=True,
xticklabels=range(10), yticklabels=range(10))
plt.xlabel('Predicted Label')
plt.ylabel('True Label')
plt.title('Normalized Confusion Matrix for MNIST')
plt.tight_layout()
plt.show()